
Musings – While I have been working on IoT related projects, there was a lot buzz around sustainability esp. Sustainability and the role of IoT in it. Thanks to my organization’s imperatives of learning, reaching a level 100 was not a big deal. During that time, I realized there are broadly two branches – Sustainability in Technology and Sustainability with Technology, my work being in the latter. While researching on this topic, along with my friend and colleague Roopa Shivani (Data Architect), we took a slight digression to investigate the literature on Green(er) Software (Sustainability in Technology – using Technology optimally to solve problems and not use everything at disposal even when it is not needed). Below is the material from the outcome – our point of view based on publicly available material on this topic.
Disclaimer: My company is part of Green Software Foundation which leads the sustainability in tech branch of industry evolution, thought leadership and standardization. This is an independent article without any proprietary information or sponsorship done at our spare times.
Abstract
In the era of moving on-premises systems to cloud based ecosystems, the basic ask from customers is about scaling the existing systems to a greater number of available resources with ease. This is aided by the seamless hardware expansion on demand, by thoughtlessly increasing the computational power in order to get the right outcomes. Our hardware systems have undergone many evolutions to accommodate high performing computational engines which obviously consume higher energy with GPUs and parallel processing. Increasing software workloads like bitcoin mining, Deep learning use cases with the need for better hardware amplifies the problem multifold. Our collective objective to remain planet friendly is to look at the opportunities where energy consumption can be reduced by designing optimum hardware and software. We look at software here as part of the below paper.
Introduction
In 2018, online video viewing generated more than 300 MtCO2, i.e., as much greenhouse gas as Spain emits: 1% of global emissions. [1] [2]
The greenhouse gas emissions of VoD (video on demand) services (e.g. Netflix and Amazon Prime) are equivalent to those of a country like Chile (more than 100 MtCO2eq/year, i.e. close to 0.3% of global emissions), the country hosting the COP25 in 2019[1][2]
The lead scientist, Rabih Bashroush, calculated that five billion downloads and streams clocked up by the song Despacito, released in 2017, consumed as much electricity as Chad, Guinea-Bissau, Somalia, Sierra Leone and the Central African Republic put together in a single year.[1][3]
Training a single natural language processing model produces as much CO2 as 315 return flights from New York to San Francisco.[1] [4]
The conservative studies estimate that the information and communication technology sector accounts for 4% of electricity consumption and 1.4% of carbon emissions worldwide .[1] [5]
The above stated and many similar studies highlight the importance of designing workloads that respect the energy for computation vs the actual need. One important concept that comes to the table is the role of Green Software which can also be read as sustainable coding. This emerging discipline puts forth the basic principles where we use the right language for the right task at hand and run it efficiently. Can this reduce the energy emissions and make our planet greener?
Green Software and Sustainable Coding
Green or sustainable software is developed and run in a way that ensures maximum energy efficiency and has minimal or no impact on the environment. There are two broad ways of looking at software in the context of sustainability – software as part of the climate problem and software as part of the climate solution. Building green software and doing it at scale requires the creation of a trusted ecosystem of people, standards, tools and best practices. The mission of Green Software Foundation is exactly that. [5]
The 8 principles of Green Software Engineering [6]
- Carbon: Build applications that are carbon efficient.
- Electricity: Build applications that are energy efficient.
- Carbon Intensity: Consume electricity with the lowest carbon intensity.
- Embodied Carbon: Build applications that are hardware efficient.
- Energy Proportionality: Maximize the energy efficiency of hardware.
- Networking: Reduce the amount of data and distance it must travel across the network.
- Demand Shaping: Build carbon-aware applications.
- Measurement & Optimization: Focus on step-by-step optimizations that increase the overall carbon efficiency.
if you want to learn more, then please take Microsoft’s free course on these above topics.
Why develop Green Software [5]
The answer lies in the two philosophies of sustainable software:
Everyone Has a Role in Fighting Global Warming and Climate Change
In this connected world every drop counts. To achieve our climate goals on a global scale, we need as many hands-on deck as possible. People with skills across industry, engineering and design are needed to create both conventional and unconventional solutions. So every sustainable line of code makes an impact.
Sustainability Alone Is Enough to Make Your Efforts Worthwhile
Sustainable software applications are often cheaper, better-performing, and more resilient than their conventional counterparts. However, the main reason to invest in green technologies should be sustainability itself. Everything else should be considered as bonus.
Benefits of Green Software [5]
While it is a given that green software engineering is for reducing carbon emissions, like every project it needs to have its own business outcomes without which any attempt at this field will die within organizations.
Some of its advantages include:
- Simpler architecture. Sustainable application architecture has fewer interdependencies. As a result, green software systems tend to be more straightforward and energy efficient. Case in point is moving to a simpler language or reducing parallel processing there by keeping the processor load low, using simpler languages and libraries.
- Faster computing speed. Simpler systems make for faster software. Single threaded powerful workhorses are sufficient if the business outcome is not affected.
- Low resource usage. Green systems use fewer resources, which translates into long-term cost savings. Either at local laptop or cloud level, resources can be reduced if we are reducing massive parallelism, consistency management, synchronization etc.
- Brand resilience. Consumers today care about the integrity and social responsibility of their service providers. By raising awareness about environmental issues and reducing your carbon footprint through green software development, you can foster brand loyalty and resilience.
A Green Software & coding handout for developers
The next obvious question would be how shall we incorporate this into our software lifecycle. Often, we look at opportunities in efficient software development during implementation. The design phase is an outcome of several analysis at depth and necessary technical guard rails have to be added during that phase, if you are serious about green software. PoCs to finalize the design and implementation should ensure best coding practices. Most of the application development functional requirement does not target lowest energy consumption (which can be at times a hidden non-functional requirement). This presents the need of targeting the principles and objectives of Green Software right from the beginning phase of software development keeping it as one of the main requirements.
What handout could we give to our architects, leads and developers to ensure they choose the right software solution respecting the functional and non-functional requirements ?
Let us look at it from SDLC perspective – whether it is waterfall/staggered/agile elements of the below ideas should go into respective areas cyclically to ensure adherence to sustainability.
Requirement phase
Coding language of choice
There are a lot of scholarly articles comparing the coding language of choice which says C++ and C being the optimal and the likes of python, typescript being the least sustainable languages. Whereas many of the image AI libraries are in python on the contrary. Hence, during the requirement phase, choosing the right language is a tricky problem for the architect or developer!
One may need to weigh in many people factors like developer availability, developer’s preference, ease of maintenance, organization’s IT priority. There is a lot of dependency between green and brown software coding languages based on their developer friendliness and organization choice [11]. Let us not confuse the green and brown here with sustainability. In this context, green is about a developer preferred language which is often used like C#, Scala or Python versus brown like C, C++, Java etc. This ensures that most of the available libraries, source code samples on GitHub are all on these languages making it even more difficult for future developers to choose another sustainable language.
Sustainable programming languages battle the above developer choices. Architects often yield to the developer affinity and organizational choice to manage project execution speed.
If we are ready to go beyond that, then we can look at green coding and software.
Here the factors to measure are time, energy and memory [12]. Depending on whether we are working on a massively parallel financial software, scheduled batch analytics of a maintenance report, an IoT device application collecting and streaming data or a machine learning algorithm, our yardsticks or weightage between the 3 factors will vary. The reference [12] details the analysis to compare the languages choosing 2 among the factors and all the 3 together, where programming language C seems to the safest choice.

Credits to original paper and the article in [12]
But we all know that C doesn’t fit into those full stack developer friendly languages. It is important that we look at application sustainability [14] deeper than the coding languages. Application workload may influence the language choice or have a larger sway on the factors like the IoT device which has low memory and need to optimize battery usage. So the jury is out there until we find the holy grail and middle path between green language for sustainability and developer love. The data here provide an initial attempt at choosing a better option.
In the context of this, what is important is to have a guidance that aligns well with good coding practices to optimize space and time complexity (that is the business case for green coding to ensure that we at least maintain the right coding practices which improves the 3 factors articulated here based on application or workload scenario).
Batch I/O operations to reduce frequent I/O access
Full read of data from filesystems to perform next operations should be done if the data size is less and within the memory capacity limits. This prevents accessing filesystem multiple times for each row/column. This will store all data in memory. All operations will then be performed in memory. If the input filesystem data is huge, full read may lead to out of memory exceptions. So ideal case would be to know the memory limits and decide whether to do a full read or read in batches which will still avoid reading every row every single time. If the scenario is real time streaming, verify if micro batch operations fulfill the requirement rather than going for line by line reading. Can this read be done on-prem without sending data to public internet reducing energy in transit?
Batch read/write records in database based on partitions if exist or Select Filter Query
Micro batch operations as well can be performed for near real time operations
Caching the objects not changing frequently. Caching is retaining not so frequently updated objects in memory. Although this prevents from accessing I/O frequently, it ends up adding cache related complexity and custom cache software.
Memory Consumption optimization
Type Sizing – One of the deciding factors of memory consumption is the size of the data type defined in the program. The smaller data type uses less memory. Despite the previous statement being so obvious, many standard programs have the assignments of integer data type while the actual value never expected to cross the boundary of size of short data type.
Analyzing the possible lowest and highest range of the actual value will help in choosing the right data type. The possibility of only non-negative(positive) values will further help in reducing the size allocation by 50%. For example, if the value is not going to exceed 32767 and cannot fall below -32768, then it is safe to declare the data type short than integer. If the value is only expected to be positive, then it can further cut short the allocation by declaring as unsigned short.
Making Garbage Collection faster
In case of .Net, when a new object is created, it is moved to Generation 0 of Garbage collection. The object keeps promoted to next subsequent higher Generations 1 and 2 if the object is still referenced. Objects in generation 0 are collected frequently and efficiently. Generation 0 holds very small memory in heap and thus least expensive while Gen 2 is the most expensive which includes the maximum memory space and is also called as Large Object Heap.
.Net exposes collect method of GC which forces the system to try to reclaim the maximum amount of available memory. All objects, regardless of how long they have been in memory, are considered for collection; however, objects that are referenced in managed code are not collected. However, The best practice is to not to call the GC.Collect() explicitly. Referencing object multiple times is expensive compared to creating objects as it keeps moving to higher generation when the existing gen level is getting garbage collected. The best way to prevent the objects moving from Gen 0 to Gen 2 is to prevent referencing objects frequently. The exception to this remark is the most used design pattern Singleton where object forever stays in memory however the intent of using singleton is for least expensive utility functions like logging, caching, database connections etc.
Weak References
The garbage collector cannot collect an object in use by an application while the application’s code can reach that object. The application is said to have a strong reference to the object. A weak reference permits the garbage collector to collect the object while still allowing the application to access the object. A weak reference is valid only during the indeterminate amount of time until the object is collected when no strong references exist. When you use a weak reference, the application can still obtain a strong reference to the object, which prevents it from being collected. However, there is always the risk that the garbage collector will get to the object first before a strong reference is reestablished.
Weak references are useful for objects that use a lot of memory but can be recreated easily if they are reclaimed by garbage collection.
Memory Leakage [15]
There are multiple ways to detect memory leakage either using profiler, task manager or diagnostic tool window. The objective here is to highlight the prime sources which may cause memory leak.
- The best practice is to use the using statement which in turn uses a try / finally statement behind the scenes, where the Dispose method is called in the finally clause.
- Unregistering the user defined event handler from the event by implementing IDisposable.
- Any type of caching mechanism can easily cause memory leaks. By storing cache information in-memory, eventually, it will fill up and cause an OutOfMemory exception. The solution can be to periodically delete older caching or limit caching size.
Efficient Data Structures, selecting less energy-greedy data structures
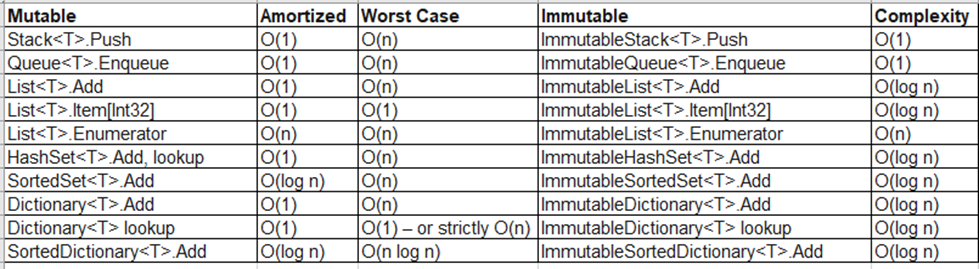
The mutable collection types in lower in algorithmic complexity to their corresponding immutable counterparts. Often immutable collection types are less performant but provide immutability – which is often a valid comparative benefit.
Approximate Programming, to reduce unnecessary precision of computations
Many applications perform computations targeting higher accuracy than required in actual which results in more consumption of resources. The objective of Approximate Programming is to deliberately reduce accuracy to save memory and energy.
In case of computations, often the double or decimal precision point is used where floating precision can just be sufficient. The below table shows the precision ranges of datatypes.
| C# type/keyword | Approximate range | Precision | Size |
| float | ±1.5 x 10−45 to ±3.4 x 1038 | ~6-9 digits | 4 bytes |
| double | ±5.0 × 10−324 to ±1.7 × 10308 | ~15-17 digits | 8 bytes |
| decimal | ±1.0 x 10-28 to ±7.9228 x 1028 | 28-29 digits | 16 bytes |
The decimal type is appropriate when the required degree of precision is determined by the number of digits to the right of the decimal point. Such numbers are commonly used in financial applications, for currency amounts.
Design Phase
Design phase efficiency depends on the deep understanding on requirement, with the ability to design the architecture framework with loosely coupled rules and abstracting the low-level information which should be flexible to extended at later steps. Define methodology to measure, report and correct deviations using platform logs.
.Net has defined reusable design patterns for multiple use cases which can be used in combination to solve the problem.
Infrastructure Design
Create infrastructure that is sufficient and scalable instead of over provisioning. In the case, of migration or optimization of existing infrastructure where workloads are run, there are tools and assets from vendors and system integrators to scan, plan and to optimize. if we need to run workloads at the edge and then cloud separately, then plan for it.
Application Design [14]
System design and platform design should be important for architects and product managers. Poor design may cause increase in energy consumption, say an UI polling a backend continuously using old world unoptimized APIs without improper caching or not co-locating servers when there is regular access needed. Such improper design can lead to lot of changes and platform refactoring later. Frequent calls over network for redundant data, an improper back-end design to represent data could be major blockers in impacting the performance and energy consumption. The design should also consider the nature of end user need and the domain criticality. For example, if the data at end user tool is not critically monitored then the use of real time pipelines can just be overkill and overutilization of resources, a simple one-time (2-3 times a day) batch process can handle the data updates instead running them every second/minute.
The experiments performed by Sahin et al. [2012] and Bunse et al. [2013] performed empirical studies where they compared the energy consumption of selected patterns. Their observation indicated that Particularly the Flyweight, Mediator and Proxy patterns resulted in energy savings when applied on selected applications, while the Singleton and Decorator pattern tremendously increased energy consumption.
Energy Optimization and Run Time Performance of Design Patterns & Data Structures
Bunse et al. focused on evaluating the energy consumption and run-time performance impact of design patterns on Android applications. The authors observed an increase in both energy consumption and execution time after applying six out of the 23 design patterns (Facade, Abstract Factory, Observer, Decorator, Prototype, and Template Method) on selected applications.
Structural changes in the design patterns can lead to significant energy optimizations as presented by Noureddine and Rajan [2015]. Their experiment revealed the Observer and Decorator as the most energy-greedy design patterns. The authors transformed the existing source code, by reducing the number of created objects and function calls and accomplished important energy savings. Specifically, after optimizing the Observer and Decorator design patterns, the authors reduced the applications’ energy consumption by 10%, on average.
Choosing the right data structure is also as important as design patterns considering some data structures are costlier than the others without any apparent additional benefits in terms of number of graph traversals versus a dictionary versus a map.
Implementation Phase
Class Libraries Performance
Avoid the need for synchronization, if possible. This is especially true for heavily used code. For example, an algorithm might be adjusted to tolerate a race condition rather than eliminate it. Unnecessary synchronization decreases performance and creates the possibility of deadlocks and race conditions.
Make static data thread safe by default.
Do not make instance data thread safe by default. Adding locks to create thread-safe code decreases performance, increases lock contention, and creates the possibility for deadlocks to occur. In common application models, only one thread at a time executes user code, which minimizes the need for thread safety. For this reason, the .NET class libraries are not thread safe by default.
Avoid providing static methods that alter static state. In common server scenarios, static state is shared across requests, which means multiple threads can execute that code at the same time. This may cause threading bugs which is highly energy consuming. Consider using a design pattern that encapsulates data into instances that are not shared across requests. Furthermore, if static data are synchronized, calls between static methods that alter state can result in deadlocks or redundant synchronization, adversely affecting performance. [11]
Parallel Programming
While parallel programming was in the cautionary list earlier, it is needed in certain other areas. This may sound contradicting but certain services on cloud are built for parallel workloads natively like Azure Data factory from Microsoft.
Data Level Parallelism
The data level parallelism is performed to run the same action on divided several chunks of data simultaneously instead either doing sequentially or running all in one go. The best approach is to divide the huge data and assign it to multiple threads/tasks to perform the action simultaneously.
Instruction Level Parallelism
While above the data is divided to perform same action, here actions are broken into parallel steps to speed up the total execution time. Here, one of the best examples can be ETL pipelines or any pipeline where the instructions like reading the data from multiple source systems can be run in parallel and different transformations based on nature of data can also be run on parallel than running as sequential steps.
Thread/Task Level Parallelism
Parallel execution of actions either my threads or Tasks are now a days over burned with the presence of easily configurable available high-end machines in the cloud. The number of threads using Thread pool or Task Parallel Library should be validated with the available configuration to benchmark the optimal numbers.
AI – Data, Storage, Training ML-Ops Cycle
Storage is cheap and getting cheaper. PaaS software gives the necessary cloud designs of replication, availability and the likes. Prebuilt algorithms to clean, learn and re-learn aided by DevOps help the MLOps run day in and day out without much value. Design should incorporate the need of the hardware infrastructure to run this MLOps and optimize it. As of today, a lot of energy is wasted in trying out newer algorithms for minimal % gains from monetary value and continuously running it.
Source Code Analysis
This is a technique by which tools detects the defects and vulnerability in software before deployment. There are many profilers or analyzer tools which efficiently detect these aspects of software. The objective is to target the following (roughly falls in performance improvement which affects energy consumption)
Unreachable code detection: Multiple such block in entire software results in blocking more unused storage.
Unused Variables: The cases where variables are declared and assigned with default value in beginning however it’s not called in the entire program. For example, defining double, string, long type of datatypes results in higher consumption of memory if not used at later stages.
Unused Functions: The functions defined but never called by any module of software.
Better code usage recommendation: The absence of efficient disposal of unmanaged resources will result in memory consumption when it is no longer needed.
There are many rules which identifies the vulnerabilities and defects as out of box feature of these tools. These tools also help in identifying the issues in code if go unnoticed.
Application Deployment
The deployment of software in dev, stage and production environment could lead to more energy consumption especially in prod if the dev ops pipeline is not well designed. Since the software is already running in 3 environments which means 3 times, the energy consumption is already high.
Evaluate how many environments we really need for a platform: while you need multiple environments could 2 environments, DevOps and a human in loop be an efficient solution as compared to 3-4 environments and end to end automation.
Minimum bugs in subsequent stages: Test Coverage should be more emphasized and automated test runs should be encouraged to detect the bugs faster and majority of bugs in dev itself. The most common practice is to keep dev environment with low power resources compare to stage and stage can be still low compared to prod environment. Hence the bugs leak into production. This repeats the test runs in all previous stages, thus the new deployment and test in production stage.
Automating the monitoring dashboards: This could be built in feature of cloud provider or third-party tool configurable which will help in monitoring overall all resources usage and help in identifying the bottlenecks.
Clean up deprecated Processes/Jobs: The development environment at times comprises of multiple combinations of tasks that are running jobs which will not be used later. It is necessary to identify the additional resources created for temporary purpose and clean them up to avoid space and energy consumption. This is application code repositories which are built even after refactoring or cleaning up.
Testing & Verification Phase
Framework, Tools and Benchmarking
The framework and tools enable the testing phase execution at ease. The benchmarking is one of the initial levels of agreement where the project decides the various KPIs to benchmark the software for its release to production. The best practice helps in defining the goals and targeting right from the initial phase.
The automated test framework development at unit test level helps in detecting the bugs at functional level and exposing the majority bugs. This reduces the number of repetitions of executions and deployment at stage or production level. The benchmarking here could be the defect leakage in subsequent stages. For example, the project team can define one of the KPI as no more than 10% of defects leakage to subsequent stage as a standard.
The code coverage tools help in detecting the efficiency of code coverage and hence reduces the additional code, memory and storage capacity. The benchmarking in percentage of code coverage sets the goal in defining the efficiency of the code. For example, the project team can set minimum 70% of code coverage for the project.
The memory and performance tools help in detecting the memory and performance imprint and hence taking actions on saving the energy.
The Load Test analyzers can be run locally and in cloud to understand the load usage of resources in that environment.
But the important point is to move away from aimless end to end automation to human monitored, AI/ML based automation in the DevOps world else we will be running large verification cycles without any major gains and with large energy expenditure.
Conclusion
There may be a lot more viewpoints out there. These are something that authors felt is a good starting point to debate on this. The above may seem like a summary of best coding guidelines from last decade. Partly that is true. We knew this.
Commonsense design, coding and management may make our software more carbon efficient.
To conclude, the authors here believe that soon enough the software editors like visual studio with plugins will be available to give options and suggestions to coders, much like Grammarly and Microsoft word suggestions to authors like us, to use an alternate expression or data structure based on the engineering and domain related benchmarks. Add to that an expert’s careful consideration of the technical requirement and business need behind it – functional and non-functional.
References
[1] https://www.zartis.com/what-is-green-software-and-business-benefits
[3] https://www.bbc.com/news/technology-45798523
[4] https://arxiv.org/abs/1906.02243
[5] https://www.zartis.com/what-is-green-software-and-business-benefits/
[7] https://michaelscodingspot.com/application-memory-health/
[9] https://dl.acm.org/doi/10.1145/3337773
[10] Software Development Life Cycle for Energy-Efficiency: Techniques and Tools by STEFANOS GEORGIOU, Athens University of Economics and Business, Singular Logic S.A. STAMATIA RIZOU, Singular Logic S.A. DIOMIDIS SPINELLIS, Athens University of Economics and Business
[11] https://michaelscodingspot.com/find-fix-and-avoid-memory-leaks-in-c-net-8-best-practices/
[12] https://earthly.dev/blog/brown-green-language/
[13] https://thenewstack.io/which-programming-languages-use-the-least-electricity/
[16] https://docs.microsoft.com/en-us/dotnet/standard/threading/managed-threading-best-practices
