This conceptual paper introduces the MVH Arc — a framework describing the trajectory by which high-performing professionals, particularly in the technology sector, migrate from being Most Valuable Humans to Minimum Viable Humans. Drawing on peer-reviewed research, WHO data, and industry-specific burnout studies, it argues that the human capabilities being systematically eroded by overwork culture are precisely those that the next decade of AI-augmented work will demand most. The framework is not academic in origin. It is observed. The author writes from the middle of it. It is a conceptual framework presentation at best which can further be explored for realistic empirical studies.
1. The Observation
My LinkedIn feed on a Tuesday morning this week contained 5-10 promotion announcements, 10+ certifications on various AI technologies and two obituaries.
From confetti graphics to AI certification badges to phrases like “excited to announce” to the photograph of the person in early forties perhaps was celebrated for promotion in another cycle.
Nobody connected the two posts. Nobody ever does unless you are the one closely affected.
2. The Connect
This article is an attempt to connect them (submitting that corelation is not causality), not through grief, but through a framework. A framework that I am naming the MVH Arc, and which I am documenting here with a timestamp, because I believe the next decade will make it necessary.
So let me state something controversial. You can call it my journal if you think it is untrue.
“The most valued professional is often the least “valuable” person in the room — and increasingly, the least likely to survive the decade in one piece.
If you’ve spent years becoming “indispensable” at work, this is probably happening to you - Senior ICs transitioning to leadership, managers in delivery pressure environments and other high performers gunning to be partners
3. Is this Anecdotal?
Is the crisis merely anecdotal? — Maybe not.
If overwork is a civilisational problem for the middle aged professional, the technology industry is its leading edge.
The sector that built the tools for always-on productivity has applied those tools most aggressively to its own people.
As for me, I didn’t notice this shift happening. It didn’t feel like a drop. It felt like growth. More responsibility. Bigger projects. Higher stakes.
But somewhere along the way, I optimized everything except being human.
4. Evidence
65% of engineers reported experiencing burnout in the past year. The 2025 LeadDev Engineering Leadership Report found only 21% of engineering leaders could be categorised as genuinely healthy — meaning the vast majority are operating in some state of depletion. [1]
67% of IT professionals report experiencing burnout, with System Administrators and DevOps Engineers recording the highest stress levels of any technical role.[2]
Perhaps the most clinically precise description of what is happening in the sector comes from a 2025 study of technology founders by CEREVITY, which introduced the term shadow burnout — defined as persistent exhaustion, cynicism, and reduced efficacy hidden behind continued high performance. The study found that 73% of surveyed founders met the criteria, with 68% actively concealing mental health struggles from investors and board members. [5]
5. My Interpretation
I may argue this is true for high performing professionals within many organizations, often working with high agency and semi-enterpreneurial or highly technical expertise often having to take decisions with platform implications. They are often in AI-induced technostress as mentioned in the Cerevity article, constantly under pressure to know it all, show it all, guide it all and what not!
Every other project and product team will have such an individual often attributed for visionary skills and remarkable turnarounds. Compressed learning and delivery cycle may eventually take a toll on these type of individuals. They will go broke and become less of a human, degrading in parts, if not in full.
6. The Framework Introduction
The Framework: From MVH to MVH – The just career arc for technologists/high performers
We perfected the MVP lingo — Minimum Viable Product. Ship fast. Ship lean. Learn and iterate later.
And the other MVP – Most Valuable Professional became its greatest achievement — certifications, promotions, AI badges, always on, always delivering.
But somewhere between the third promotion and the fifth burnout, the Most Valuable Professional became the Minimum Viable Human.
Functional. Deployable. Impressive on paper. Running on fumes and external validation..
Let me call this progression as
MVH Arc –
Most Valuable Human to Minimum Viable Human
The most expensive journey you'll ever take. And the destination and the story arc are not really worth it. Let's admit that not all of are Mr. Robot from the series changing the world through anarchy.
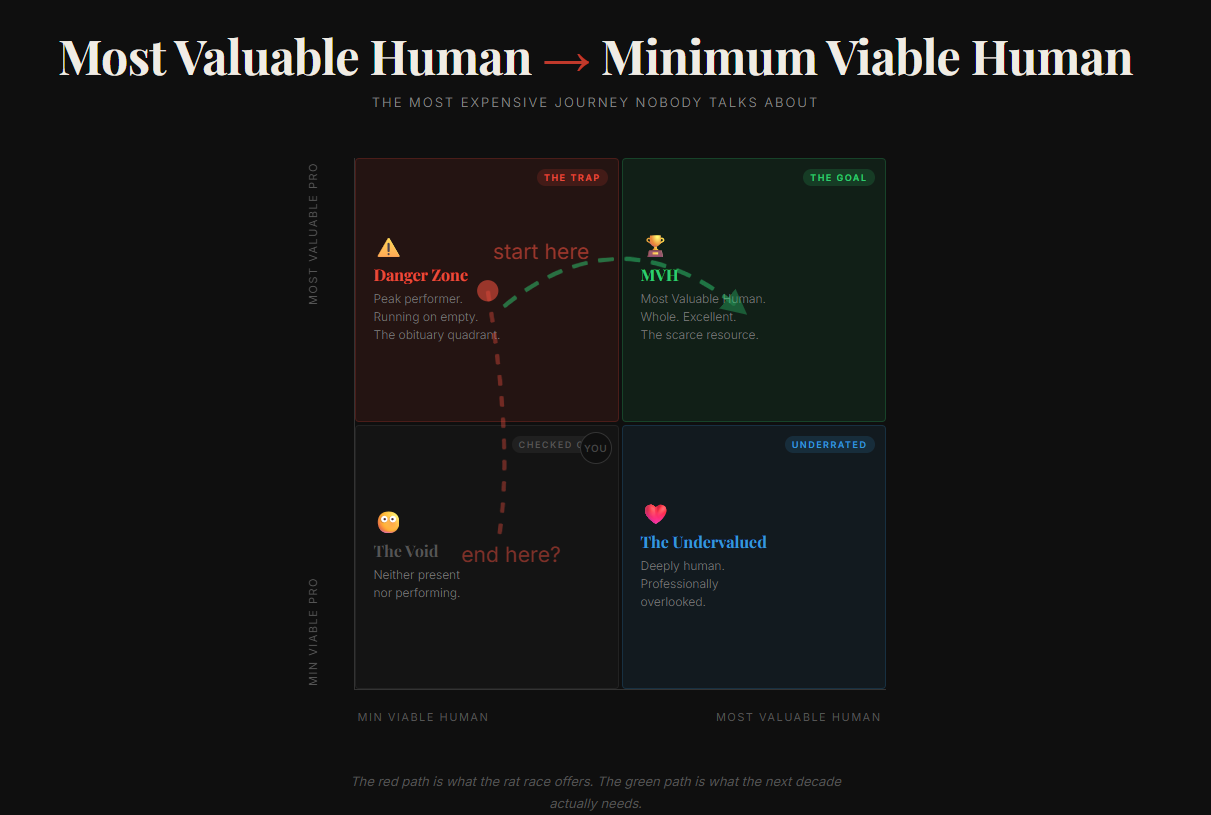
You know this person. You might be this person.
They show up. They deliver. They’re always on. But ask them the last time they laughed without checking their phone, sat with a friend without half a mind on a deadline, or simply did nothing — and watch them go quiet.
They haven’t disappeared. They’ve just been… optimized.
7. The Irony
The decade ahead won’t be won by the most optimized human in the room. That’s for the agent to be.
It will be won by the most human human in the room.
People with judgment. Empathy. Presence. The ability to sit with another human being and actually see them. That is the scarce resource AI cannot manufacture.
These are what AI cannot replicate. And we are systematically destroying them in ourselves, in the name of growth.
The decade ahead desperately needs Most Valuable Humans and less of MVPs.
8. Where am I?
I’ll be honest because this post deserves honesty. I have never been the most valued human in my own evaluation.
I have measured myself in output, in delivery, in whether I was useful enough. The professional scorecard was always full. The human one I kept meaning to get to that. This post isn’t wisdom from the other side. It’s a note from the middle of it while the change is in progress.
9. What do you do?
Track energy, not just output
Design “no optimisation zones” (health, family, thinking time)
Don’t let career growth outrun identity stability. Be identifiable in the end.
Drift & yet remain purposeful, like a solid, driftwood.
10. In conclusion
Most people don’t burn out.
They slowly stop being fully human.
And nobody notices — because the system rewards it.
The rat race doesn’t announce itself as dangerous. It just asks for a little more.
One more late night. One more certification. One more quarter.
FOMO does the rest because everyone else seems to be sprinting within the same cage. So stopping feels like failing until we faint.
But the most valuable thing you can be in the next ten years isn’t the most optimized professional in the room.
It’s a whole person who showed up. Someone worth knowing, not just worth hiring.
11. Remember
You are not a product. Stop shipping yourself into the ground.
There’s a better GitVersion of you out there, imperfect and unoptimized. You are not a costly GPU!
Know your life’s pace before you outpace.
Don’t be “Certified” Dead, at some point we all will anyway be one!
Don’t go from most valued to minimum viable human.
~ From one MVH professional to another ~
References
- Wellhub. (2025). U.S. Work-Related Stress in 2025: Key Stats & Solutions. wellhub.com
- DORA / Google Cloud. (2024). State of DevOps Report 2024. As cited in IT Support Group, 2025. thisisanitsupportgroup.com
- State of Engineering Management Report (2024) as cited in CIO Magazine (2025); LeadDev. (2025). Engineering Leadership Report 2025. leaddev.com
- Ketamine MC. (2026). Is the Tech Industry Facing a Mental Health Crisis? ketamc.com
- CEREVITY. (2025). Shadow Burnout Among California Tech Founders: The Hidden Crisis Behind High Performance. Survey of 127 founders conducted January–December 2025. cerevity.com
- Loaiza, I. & Rigobón, R. (2025). The EPOCH Framework. MIT Sloan School of Management. As cited in Futureneers, 2025. futureneers.io
- EY. (2026). Redesigning Work Around Human Skills in the Age of AI. ey.com



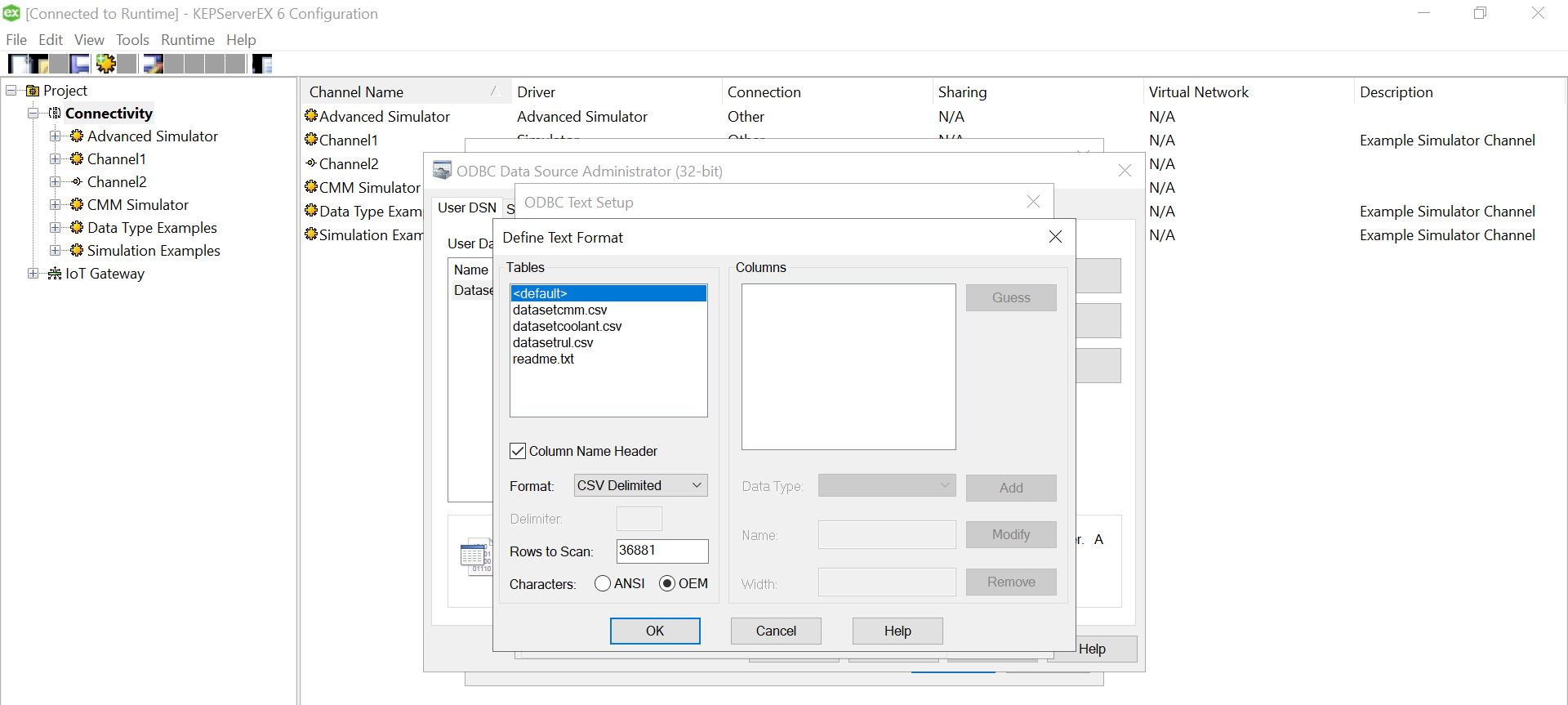
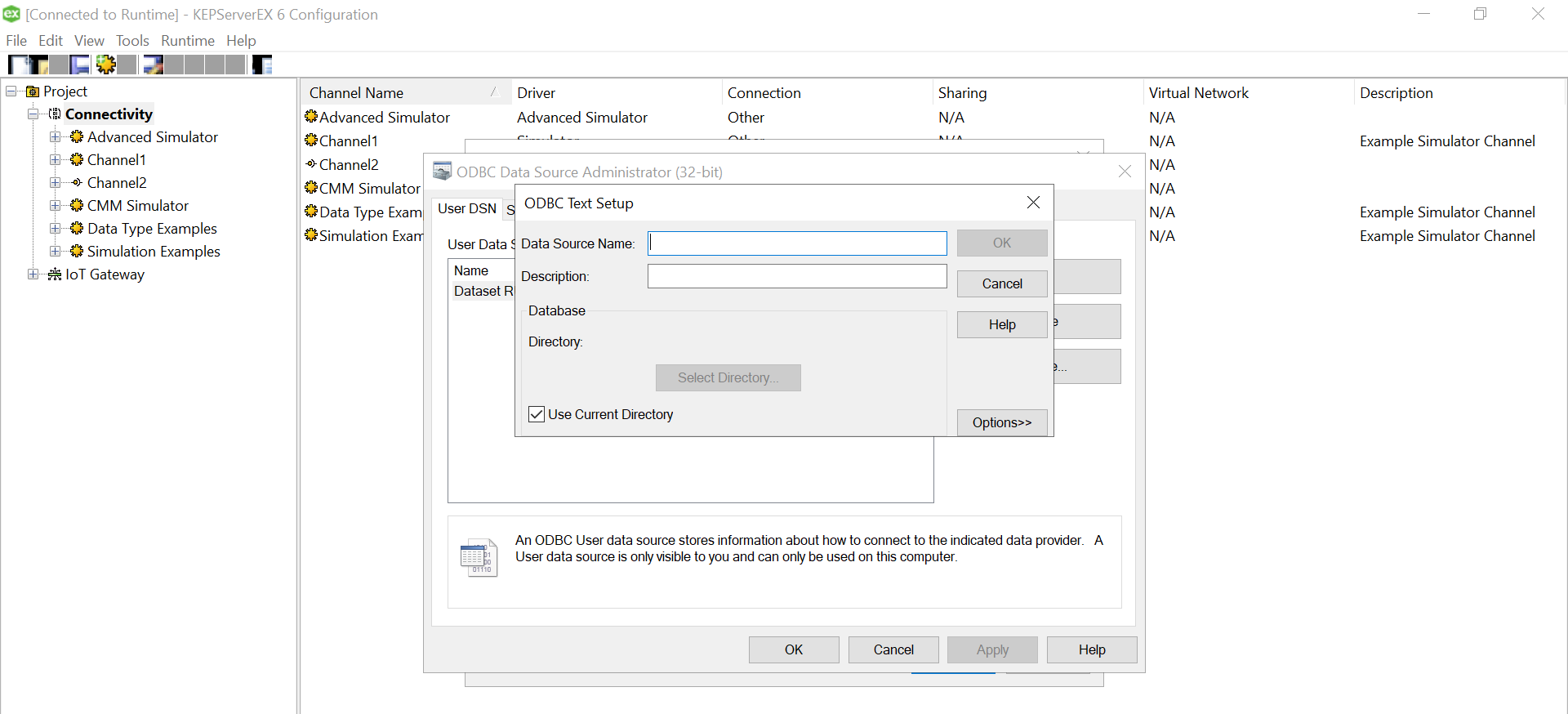 Use “Define Format” feature to select the columns and guess the tag rows. That will help you know if the file is being read correctly. If there are changes to delimiters and stuff we can give all those customizations here. We had a standard csv.
Use “Define Format” feature to select the columns and guess the tag rows. That will help you know if the file is being read correctly. If there are changes to delimiters and stuff we can give all those customizations here. We had a standard csv.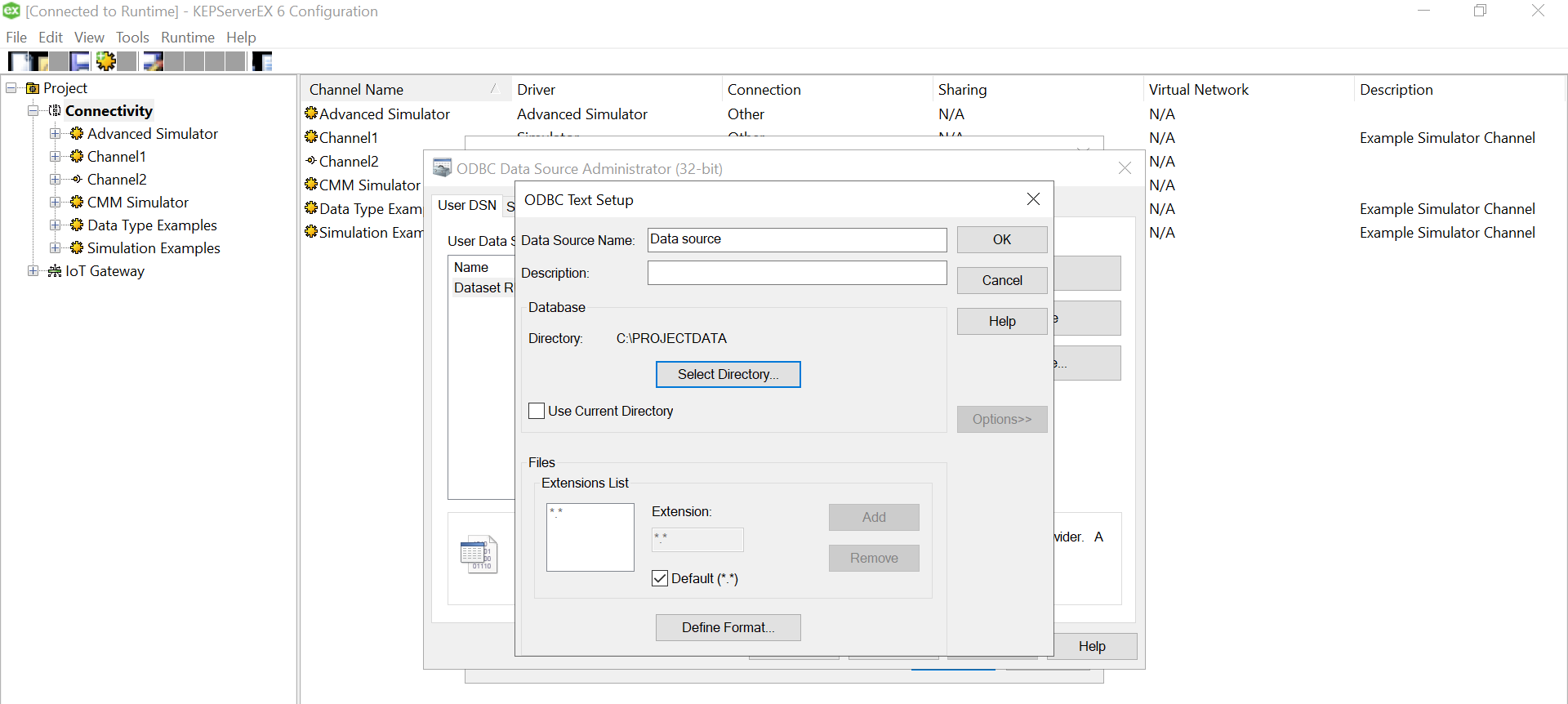
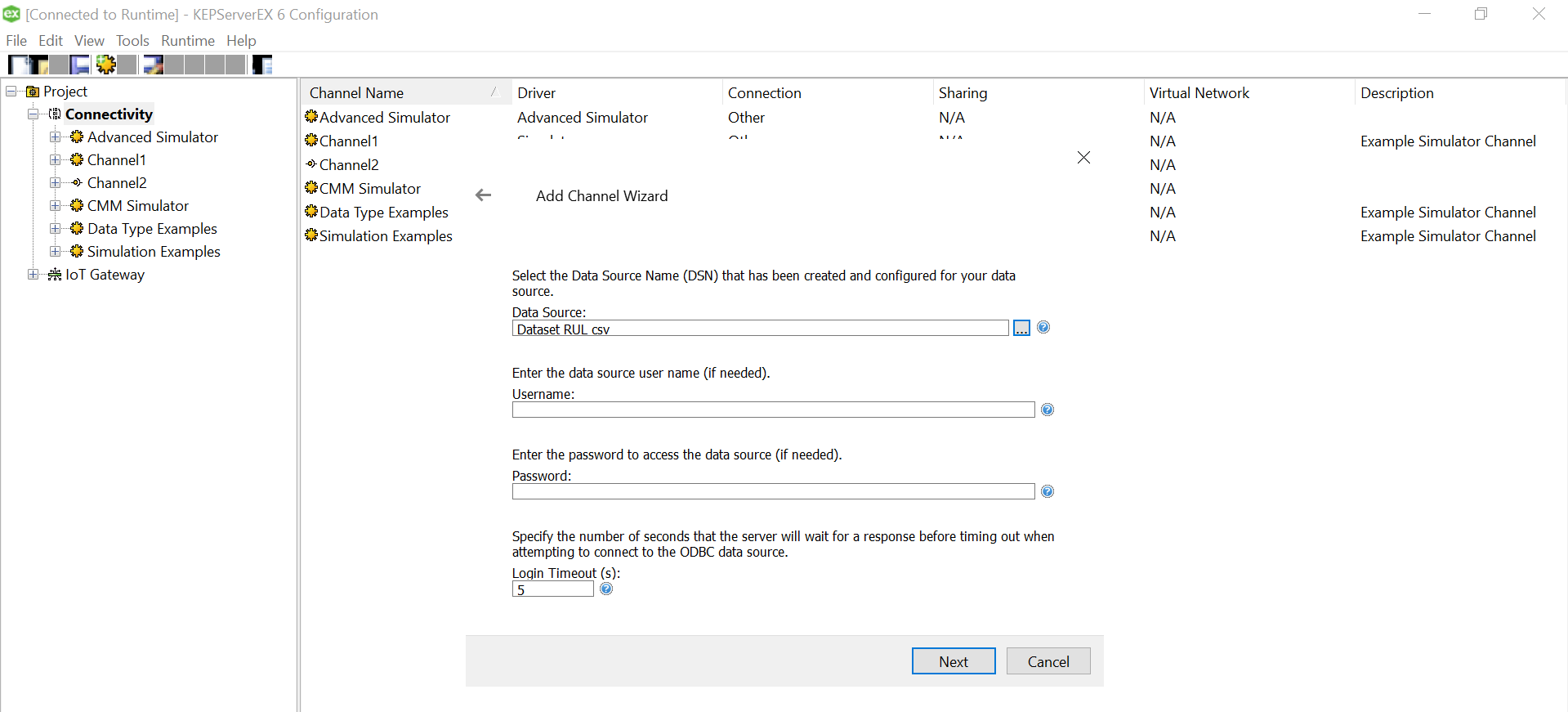
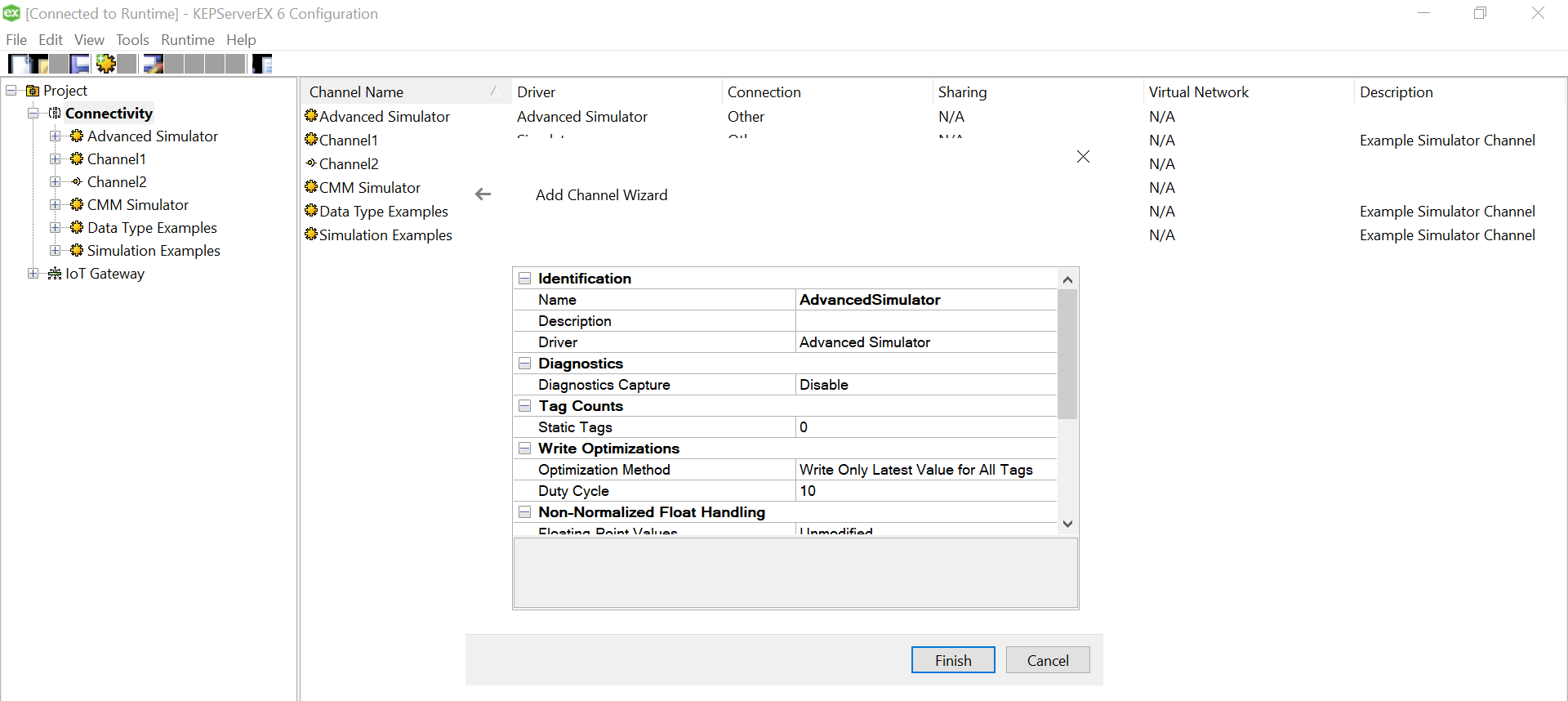
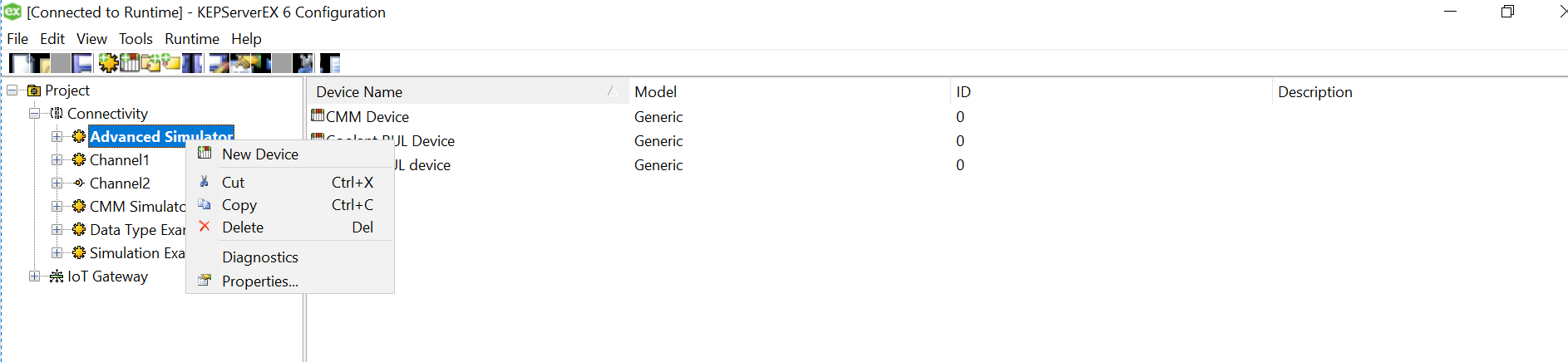
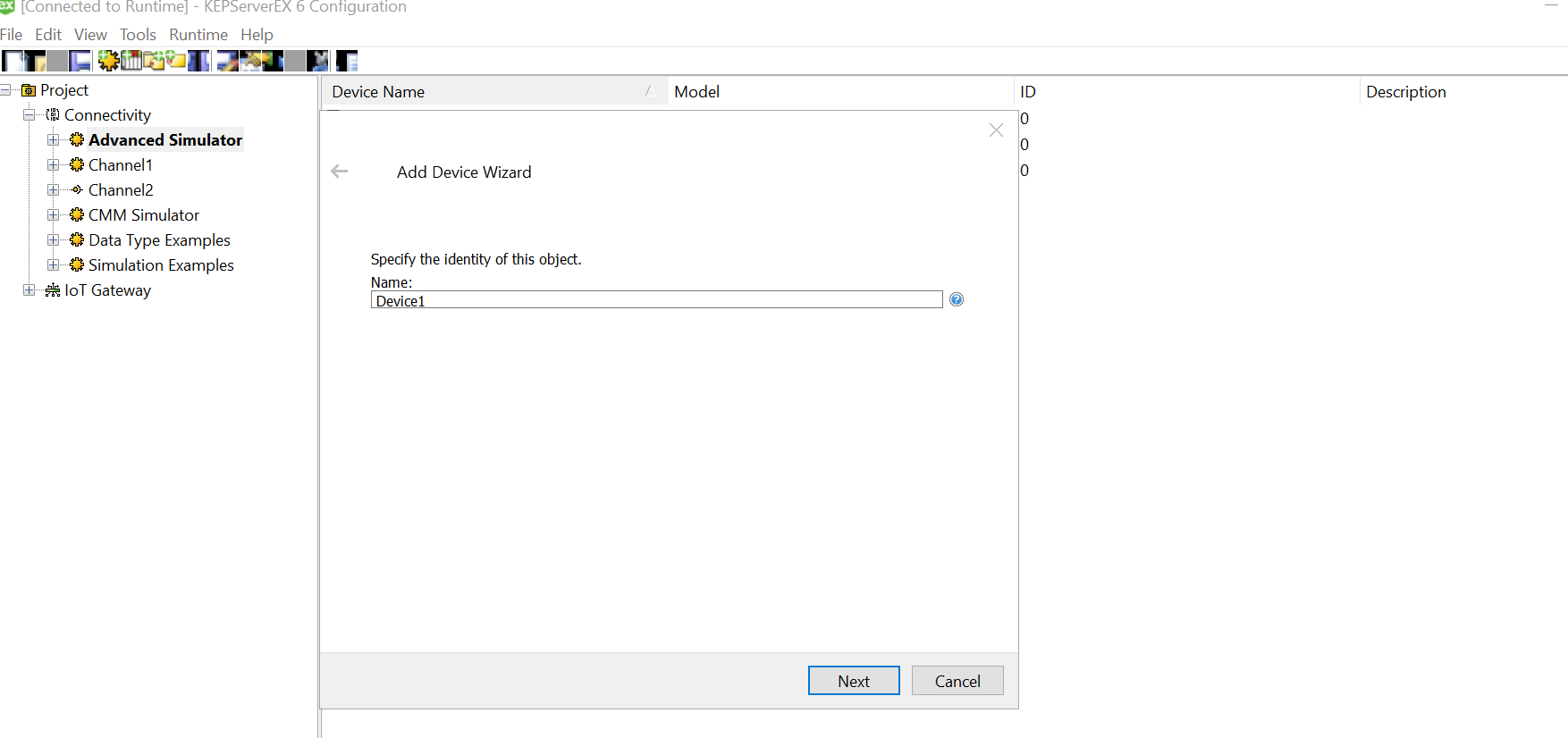
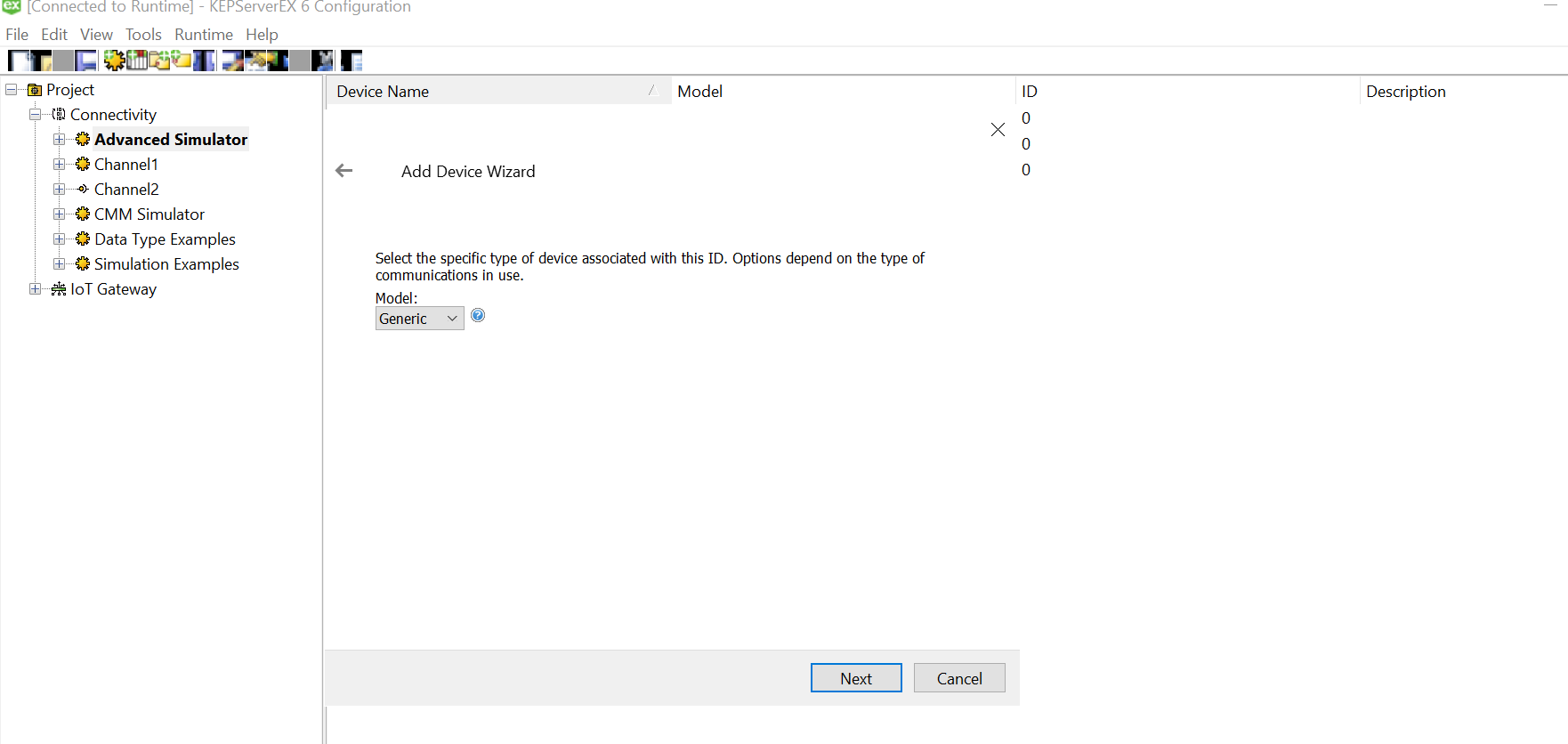
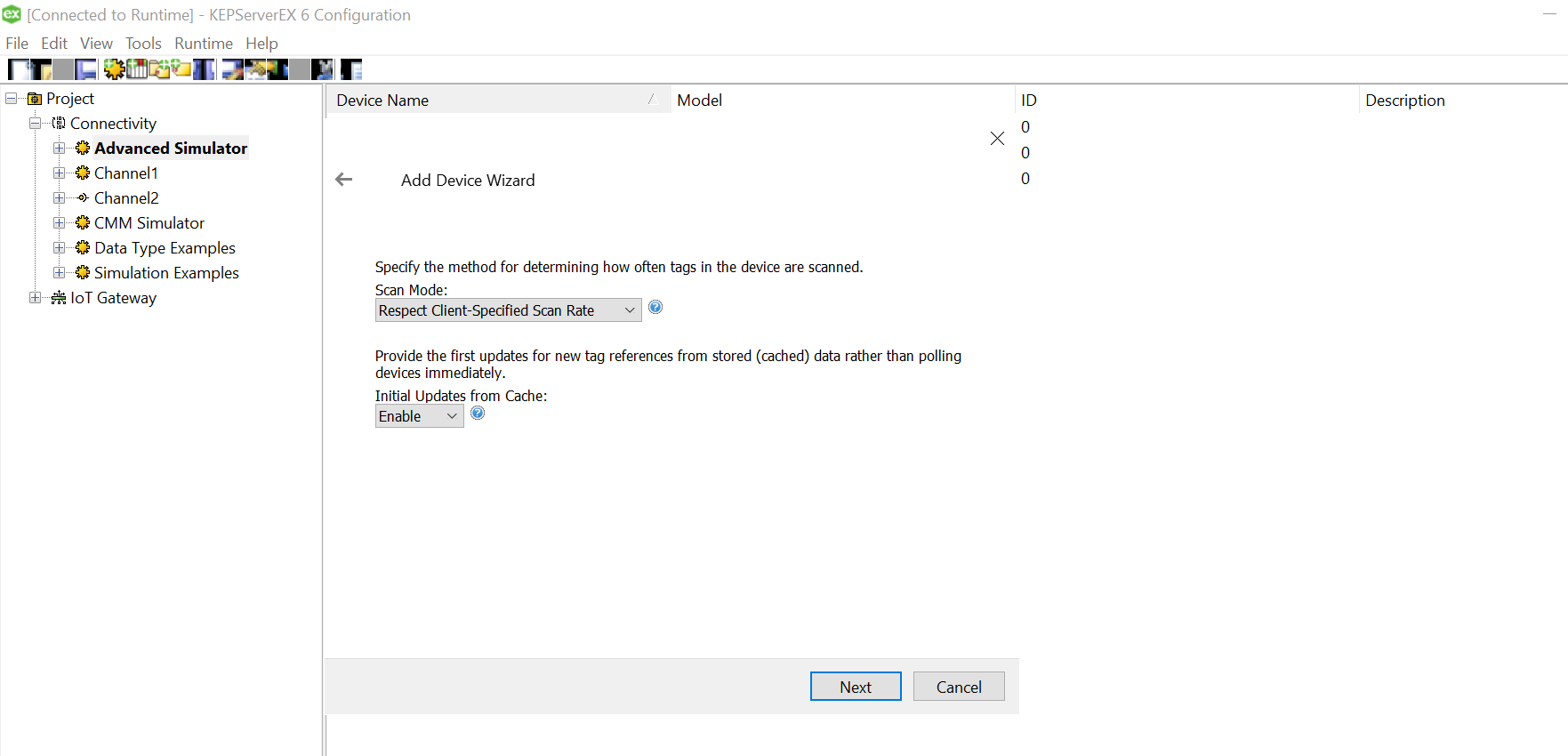
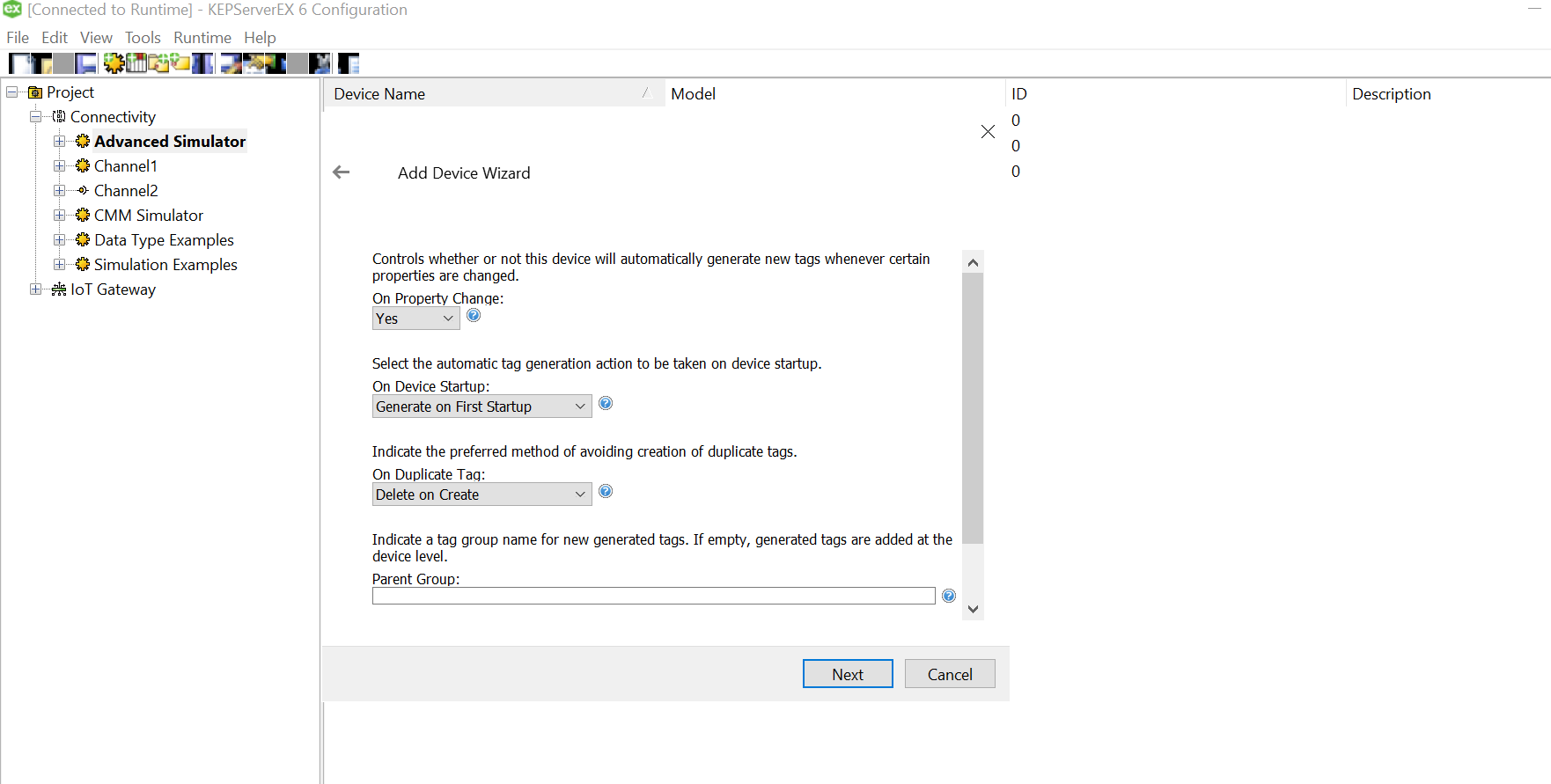
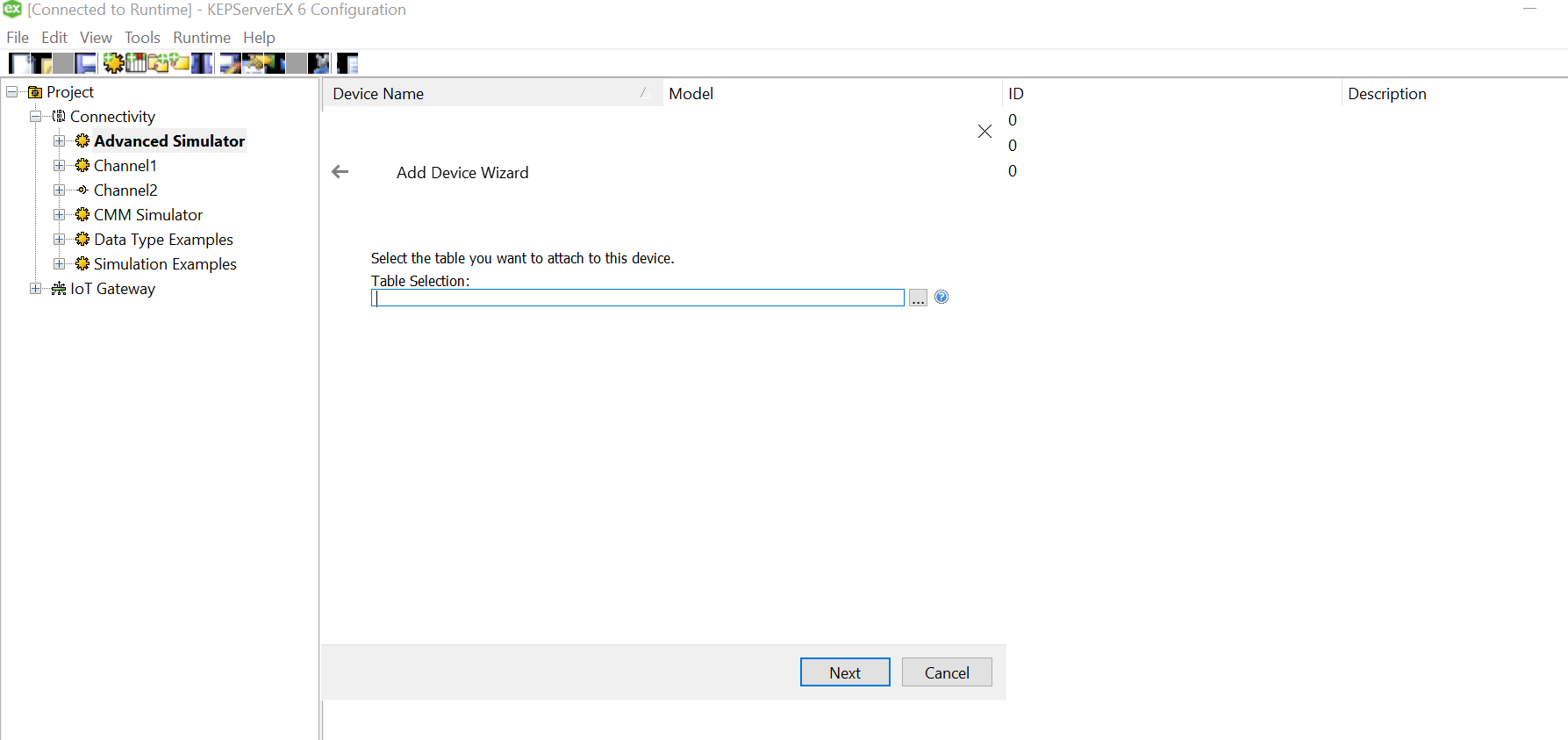 Click on the three dots and select the soecific csv for this device from the data source mapped earlier while setting up channel.
Click on the three dots and select the soecific csv for this device from the data source mapped earlier while setting up channel.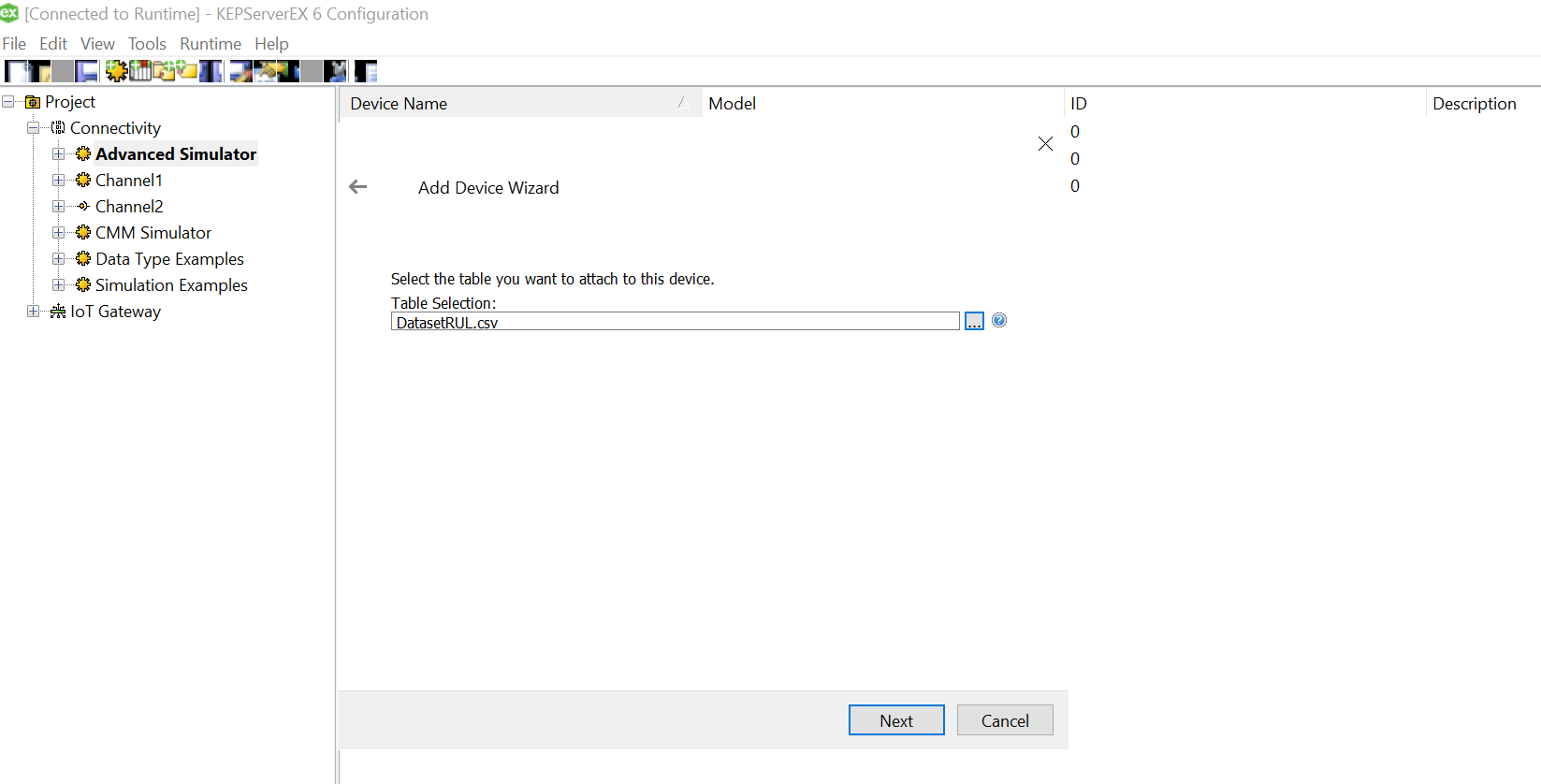
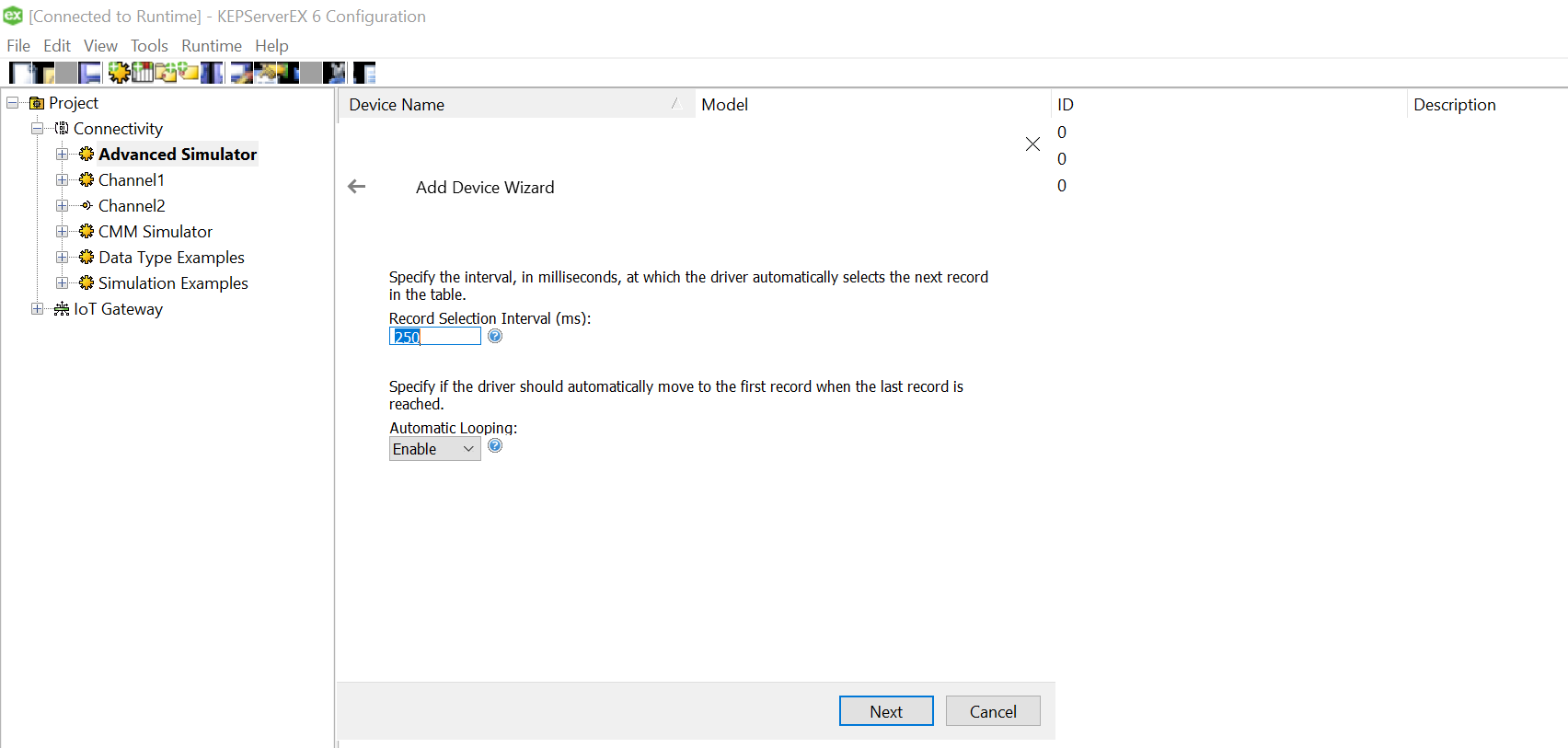
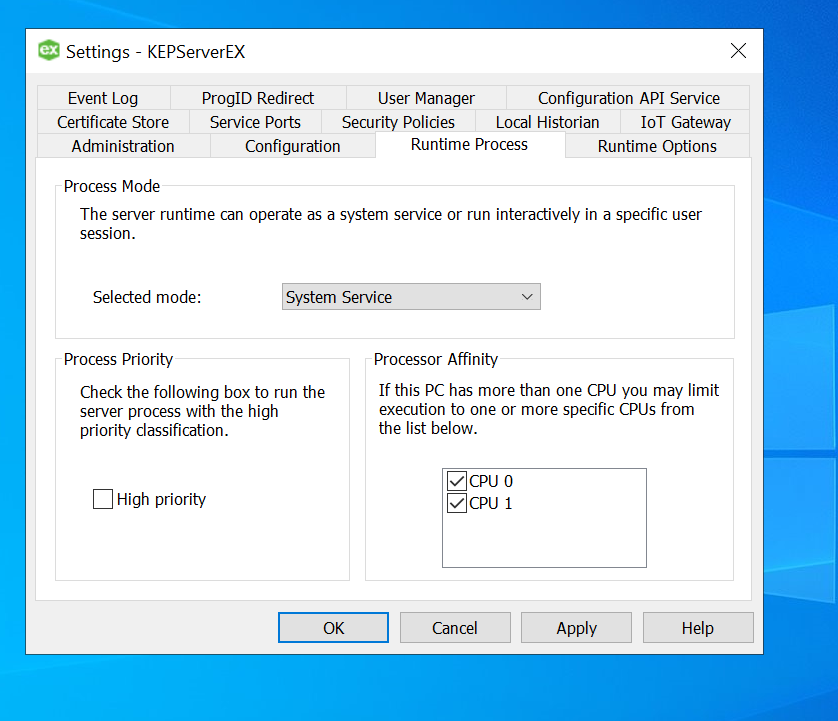
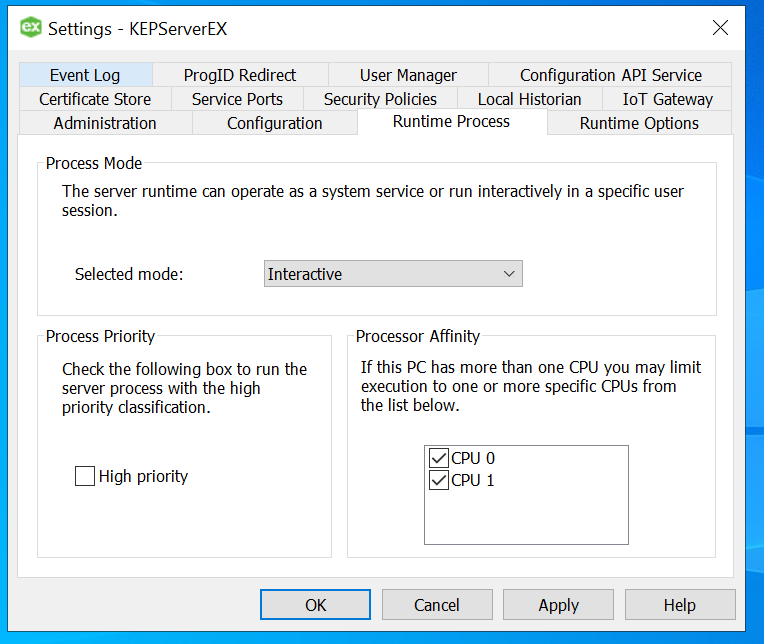
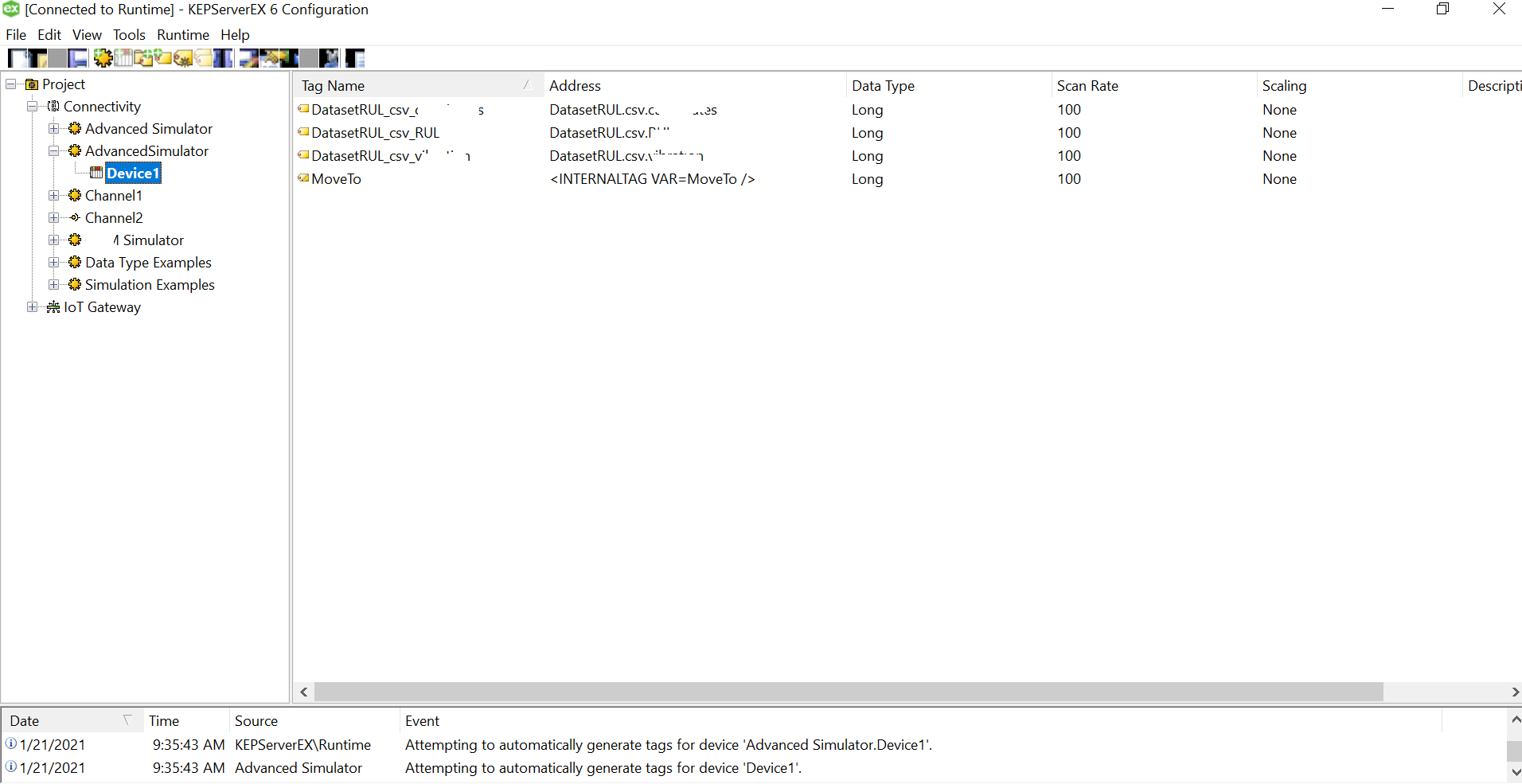
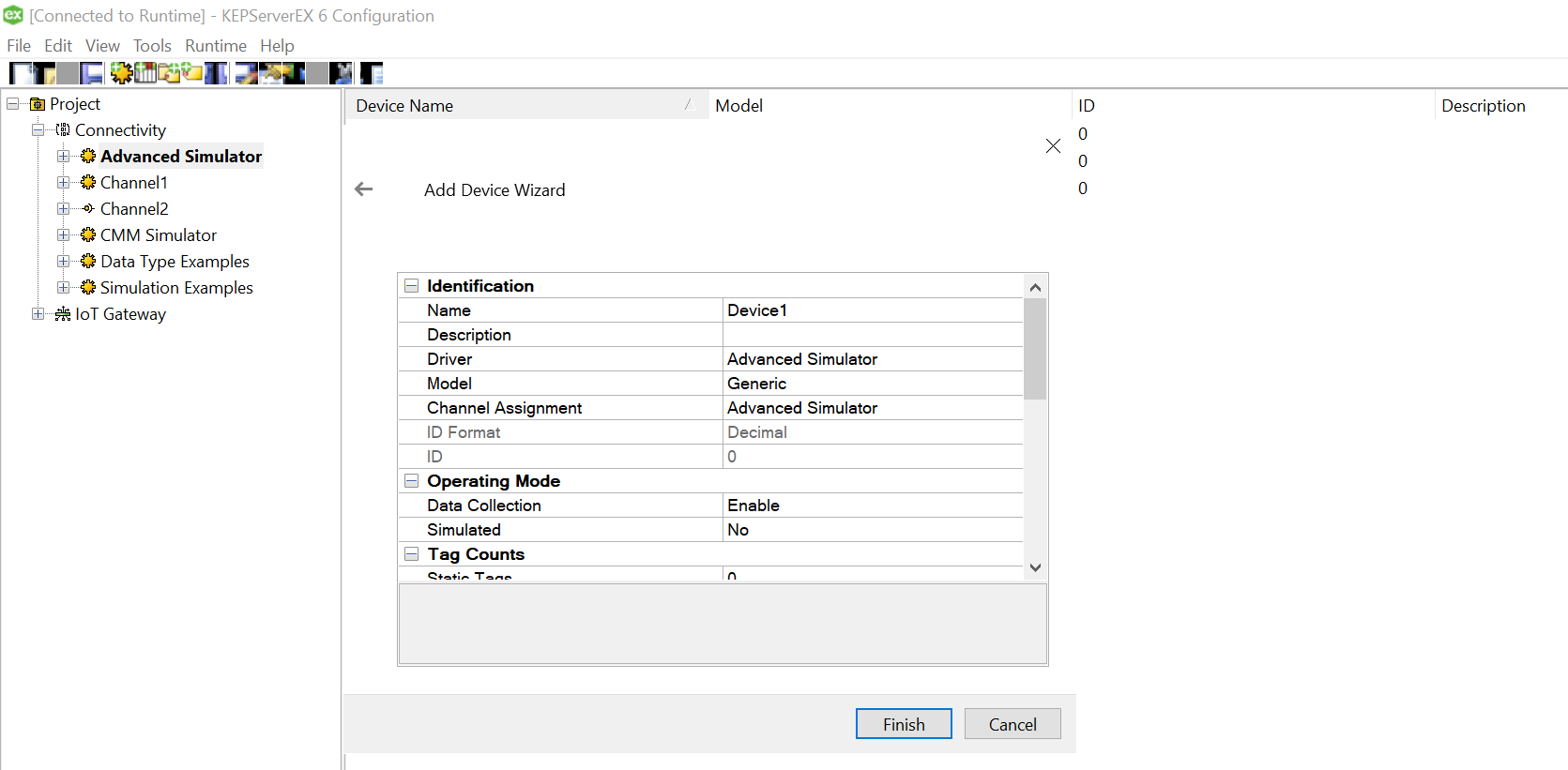 Click Finish and the device is successfully added, the driver should be able to “Generate” the TAG names from the column names. In case, the logs indicate an error as below, you may want to change OPC configuration settings to resolve it.
Click Finish and the device is successfully added, the driver should be able to “Generate” the TAG names from the column names. In case, the logs indicate an error as below, you may want to change OPC configuration settings to resolve it.





 Lohith followed that up with a session on Telerik and their amazing Xamarin Forms controls for new wave of cross-platform applications. He showed some interesting demonstrations of the many controls that they have custom-made for Xamarin Forms. This session was especially handy for the folks from enterprise who were there for this session. They had specific questions on how it could be leveraged for their existing applications and Lohith answered to them happily. More information can be found
Lohith followed that up with a session on Telerik and their amazing Xamarin Forms controls for new wave of cross-platform applications. He showed some interesting demonstrations of the many controls that they have custom-made for Xamarin Forms. This session was especially handy for the folks from enterprise who were there for this session. They had specific questions on how it could be leveraged for their existing applications and Lohith answered to them happily. More information can be found 




